In this blog post(Routing Algorithms In Computer Networks), we are going to explore Which routing algorithm is best? What are the types of routers? What are the different types of static routing? What is routing in a computer network?
Which routing algorithm is best?/Routing Algorithms In Computer Networks?
The distance vector routing algorithm is considered the best routing algorithm.
This determines the best route for the data packet in the network.|Routing Algorithms In Computer Networks|
What are the types of routers?
The types of routers are listed below:
Wire and wireless routers
Core and edge router
Virtual router
What are the different types of static routing?
There are various IPv4 and IPv6 routing static routes which are listed below:
Standard static route
Default static route
Summary of a static route
Floating static route
What is routing in a computer network?
Routing is defined as a way by which IP data packets travel from their origin to their destination. Or IP data packets travel from sender to receiver.
Hello Friends, In this blog post I am going to let you know about the different types of routing algorithms.
The types of routing algorithms are given below.
Non-adaptive routing and adaptive routing
Centralized routing
distributed routing
Isolated routing
Non-adaptive Routing Algorithms:
Non-adaptive routing algorithms do not base their routing decision on measurements or estimates of the current traffic and topology.
Instead, the choice of the route to use to get from I to J is computed in advance, off-line, and downloaded to the routers when the network is booted. This procedure is sometimes called static routing.
Adaptive Routing algorithms:
Adaptive routing algorithms, in contrast, change their routing decisions to reflect changes in topology and usually the traffic as well.
The adaptive algorithm differs in where they get their information from when they change the routes and what metric is used for optimization(e.g., distance, number of hops, or estimated transit time).
Centralized Routing Algorithms:
Centralized routing algorithms mean that all interconnection information is produced and maintained at a single central location.
Then, this information is broadcast by the location to all the networks so that each may define its routing tables.
For maintaining routing information centrally, one method is the routing matrix. It has a row and column for each node in the network.
A row corresponds to a source node and a column to a destination node.
The first node in the route is indicated by the entry in the position specified by the row and column from source to destination.
The entire route can be extracted from this entry.
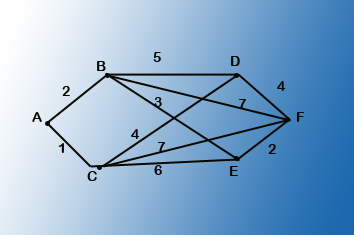
The routing matrix for the network in fig1 is shown in fig2. The routes selected are the cheapest ones. If there are two routes both have the cheapest cost, then one is chosen arbitrarily.
Again, consider the route from A to F. It can be seen from the matrix’s first row and sixth column that node B is the first one in the cheapest route.

The next state is obtained by considering the route from B to F. It can be seen from the second row and sixth row that node E is next.
At last, the node following E(node F) is obtained in the fifth row and sixth column.
Therefore, the route is from A to B to E to F.
Creating a routing table for a network node needs the row from the matrix corresponding to the node.
Distributed Routing Algorithms:
In distributed routing algorithms, there is no central control. Each node must decide and maintain its routing information independently.
It usually does this by knowing who its neighbors are, calculating the cost to get there, and deciding the cost for a neighbor to send data to specific destinations.
Then the same thing is done by each neighbor. From this information, each node can obtain its routing table.
In comparison to centralized routing, this method is more complex because it needs each node to communicate with each of its neighbors independently.

Fig 3 shows a distributed routing network. Suppose that initially, each node knows only the cost to its neighbor.
Later it can add to its information base anything its neighbors tell it.
For example, A initially knows only that it can send something to B (cost=1) or D(cost=2).
It does not know whatsoever that nodes C and E even exist.
Other nodes have the same knowledge(or lack of it). If neighboring nodes communicate, A learns the identity of B’s and D’s neighbors and soon learns of nodes C and E.
Node A can calculate the cost to get there and know the cost to get to B and D.
Everyone learns the identity of others in the network and the cheapest paths to them by periodically exchanging information about the neighboring node.
Isolated Routing Algorithms:
In static routing(Isolated routing algorithms), once a node determines its routing table, the node does not change it.
This can be said in another way that the cheapest path is not dependent on time.
There is an underlying assumption that the conditions which led to the table’s definition have not changed.
Sometimes this assumption is valid because costs often depend on the distance and the data rates between intermediate nodes.
These parameters do not alter except for major equipment upgrades and moving of equipment.
You can also go through a few more amazing blog links below related to Computer Networks:
What is a domain name system with an example…
World Wide Web In Hindi…
The Leaky Bucket Algorithm In Hindi…
Difference between TCP and UDP In Hindi…
UDP: User Datagram Protocol…
How does Multicast routing work…
What is Unicast routing protocol…
Routing Algorithms In Computer Networks…
What is a routing table used for…
DNS(Domain Name Server or System) Server In Hindi…
Conclusion:
Using this blog post(Routing Algorithms In Computer Networks) we have gone through What is the Network Layer routing algorithm explained with an example, What are routing algorithms, What is distance vector routing algorithm, and Which routing algorithm is best? What are the types of routers? What are the different types of static routing? What is routing in a computer network?
In the case of any queries, you can write to us at a5theorys@gmail.com we will get back to you ASAP.
Hope! you would have enjoyed this post about routing Algorithms In Computer Networks.
Please feel free to give your important feedback in the comment section below.|Routing Algorithms In Computer Networks|
Have a great time! Sayonara!